GSTA
- The source code and data of the paper “GSTA: gated spatial–temporal attention approach for travel time prediction”
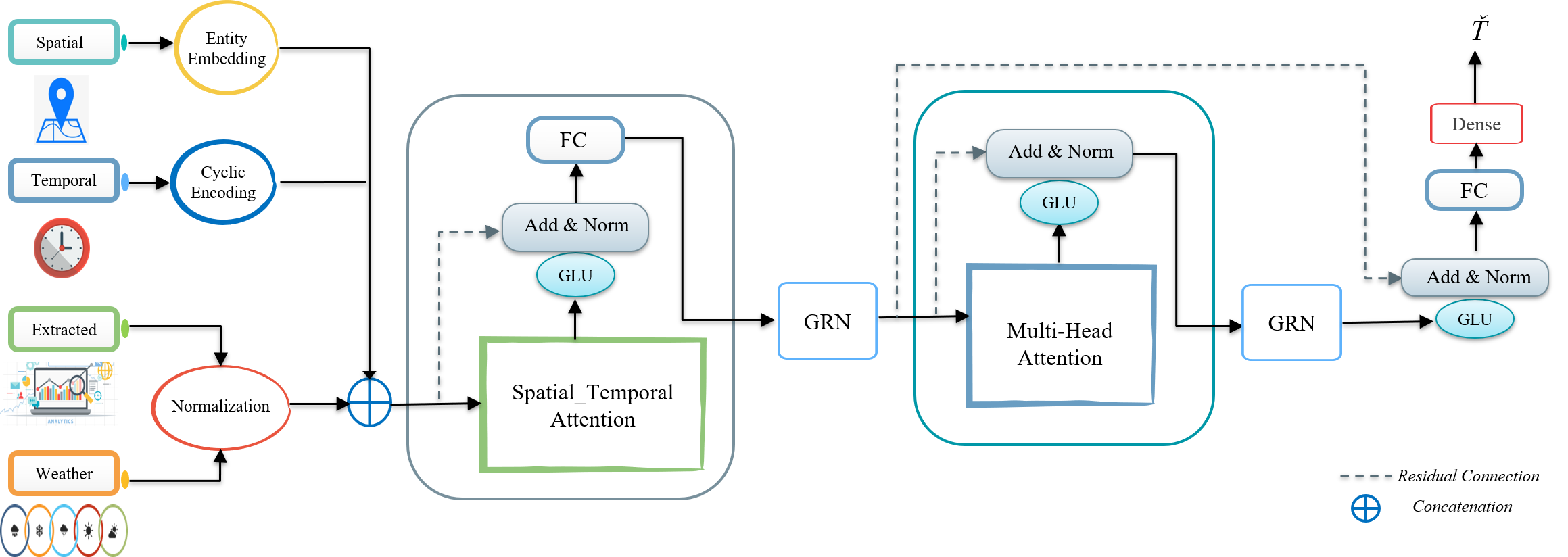
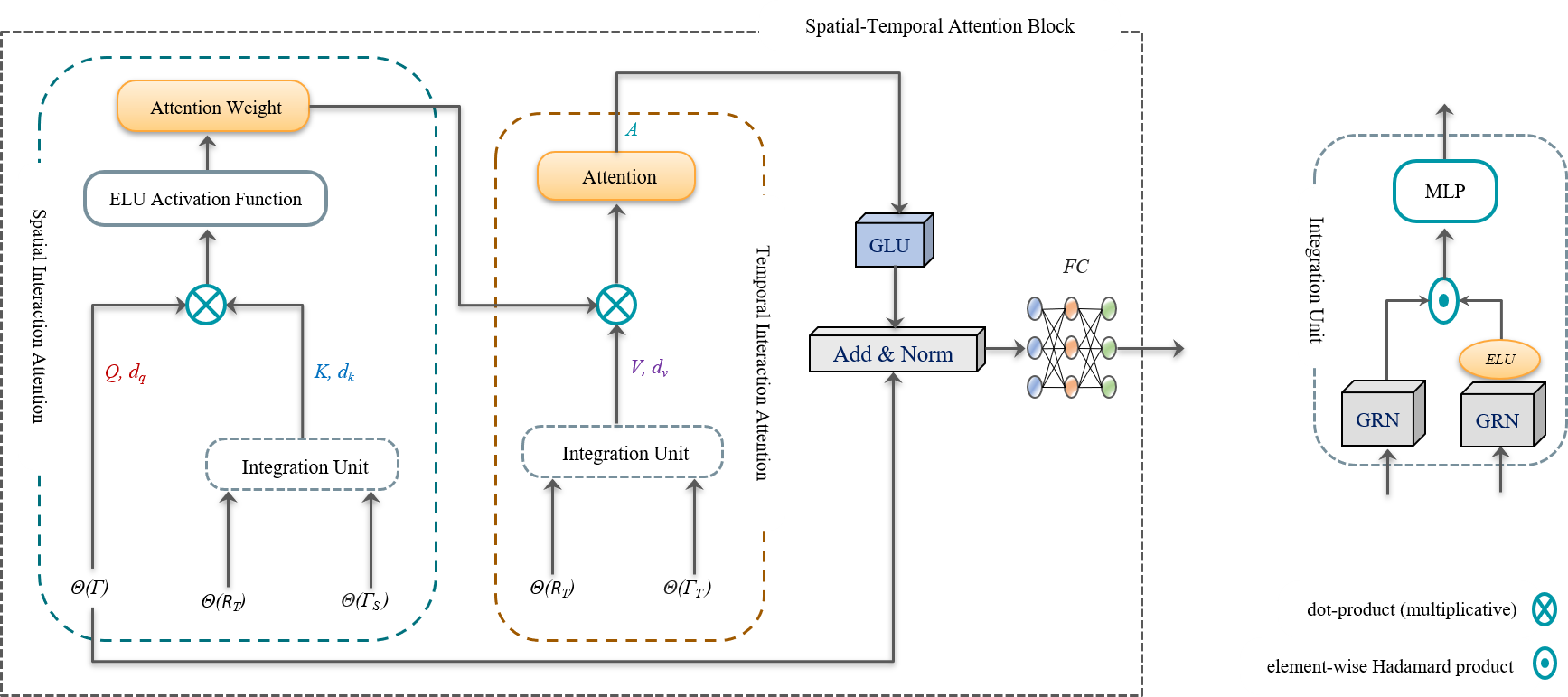
Spatial-temporal Attention
Data
- A sample of 81K trips is provided for each of the NYC and Chengdu Taxi datasets in folders (NYC Data, Chengdu Data).
- The data samples are already pre-processed (Data Cleaning, Feature Engineering,… etc) and randomly split into train (X_train, Y_train), validation (X_val, Y_val), and test (X_test, Y_test).
- The implementation of the prediction model for each dataset is given in a separate jupyter notebook (GSTA on NYC.ipynb, and GSTA on Chengdu.ipynb).
Each data sample is a CSV file. The key contains:
- Location Features: ‘pickup_longitude’, ‘pickup_latitude’, ‘dropoff_longitude’, ‘dropoff_latitude’, ‘center_latitude’, ‘center_longitude’, ‘dropoff_pca0’, ‘dropoff_pca1’, ‘pickup_pca0’, ‘pickup_pca1’
- Cluster Features: ‘pickup_cluster’, ‘dropoff_cluster’, ‘pickup_counts_on_clusterid’, ‘dropoff_counts_on_clusterid’
- Geo-hash Features: ‘pickup_geohash’, ‘dropoff_geohash’
- Date/Time Features: ‘DayofMonth_sin’, ‘DayofMonth_cos’, ‘Hour_sin’, ‘Hour_cos’, ‘dayofweek_sin’, ‘dayofweek_cos’, ‘Weekend_day’, ‘Work_day’
- Weather Features: ‘tempm’, ‘dewptm’, ‘hum’, ‘rain’, ‘snow’, ‘wdird’, ‘vism’, ‘fog’, ‘thunder’, ‘tornado’, ‘conds_Clear’, ‘conds_Haze’, ‘conds_Heavy Rain’, ‘conds_Heavy Snow’, ‘conds_Light Rain’, ‘conds_Light Snow’
- Distance: ‘distance_haversine’, ‘distance_dummy_manhattan’
- Direction: ‘direction’
- Speed: ‘avg_speed_KMperHour’
- Public Holiday: ‘Public_Holiday’
- Peak period: ‘Peak_Hour’
- Travel Time: ‘trip_duration’
Parameters:
(These parameteres are tuned with whole dataset, you can change them manually)
The default parameters are:
- optimizer=Adam(lr=0.001).
- loss=’mean_absolute_error’
- metrics=[‘mae’,’mape’]
- Dropout=0.2
- epochs = 50
- batch_size = 256
- kernel_regularizer=l2(0.001)
- Activation(‘elu’)
- BatchNormalization(epsilon=1e-06, momentum=0.98)
- kernel_initializer=”he_uniform”
- num_heads = 4 , which is the number of heads in Multi-Head attention.
Results
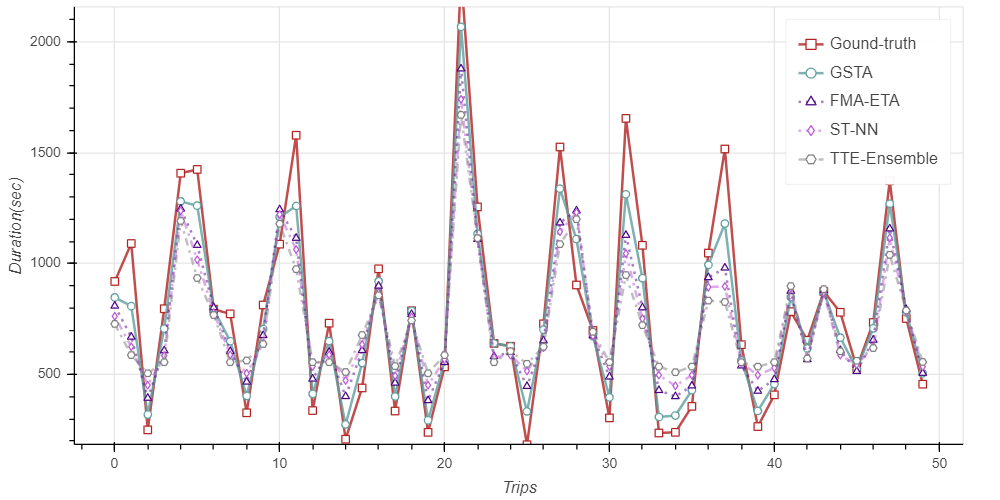
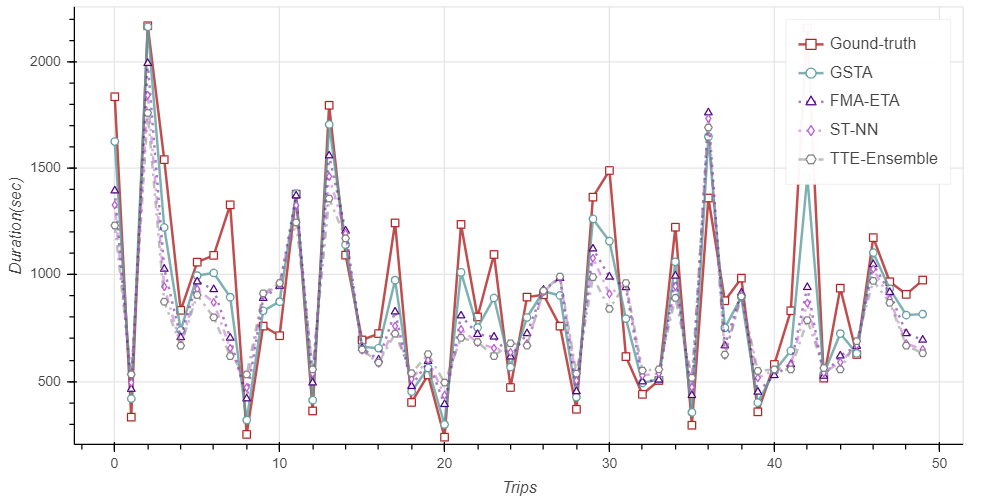
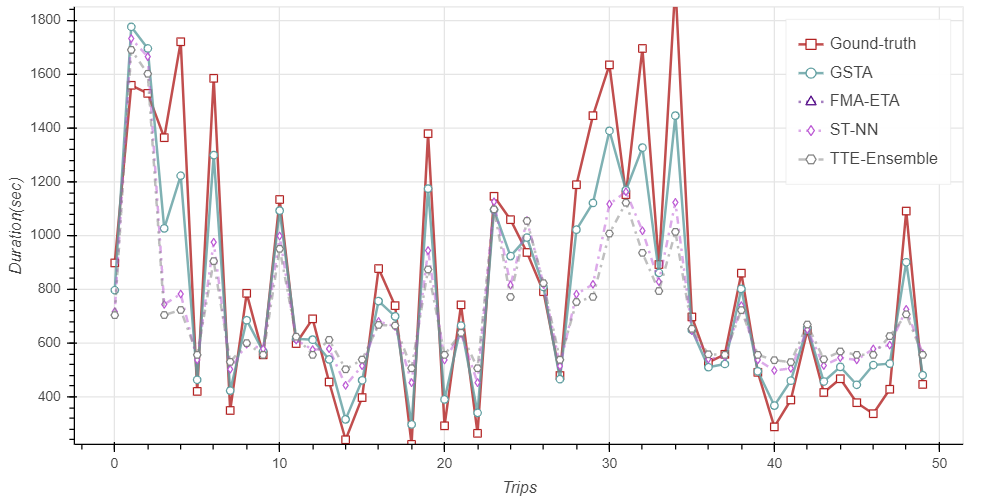
Best Model
The best model for each data during training phase is saved to folder “Models” as hdf5 file.
Dependencies:
Keras 2.4.3, Tensorflow 2.3.0, Bokeh 2.2.1, Numpy 1.19.3, Pandas 1.1.5, Sklearn.
BibTeX Citation
If you use our paper in a scientific publication, we would appreciate using the following citations:
@article{Khaled2021,
author = {Khaled, Alkilane and Elsir, Alfateh M Tag and Shen, Yanming},
doi = {10.1007/s00521-021-06560-z},
issn = {1433-3058},
journal = {Neural Computing and Applications},
title = ,
url = {https://doi.org/10.1007/s00521-021-06560-z},
year = {2021}
}